娜塔莉亚·诺伊(Natalya F. Noy) 和黛博拉·麦坚尼斯(Deborah L.
斯坦福大学,斯坦福,CA,94305
noy@smi.stanford.edu 和 dlm@ksl.stanford.edu
1. 为什么要开发一个本体?
近年来,本体的发展(对领域中术语的明确规范和它们之间的关系(Gruber 1993))已经从人工智能实验室的领域转移到领域专家的桌面。本体在万维网上已经很普遍。Web上的本体包括从对网站进行分类的大型分类法(例如在Yahoo!上)到要出售的产品及其功能的分类(例如在Amazon.com上)。WWW联盟(W3C)正在开发资源描述框架(Brickley和Guha,1999),该语言用于对网页上的知识进行编码,以使电子代理商可以轻松地搜索信息。 国防高级研究计划局(DARPA)与W3C一起,通过扩展RDF并使用更具表现力的结构来扩展DARPA代理标记语言(DAML),旨在促进Web上的代理交互(Hendler和McGuinness 2000)。现在,许多学科都在开发标准化的本体,领域专家可以使用它们来共享和注释其领域中的信息。例如,医学已经产生了大型的,标准化的,结构化的词汇,例如SNOMED (Price和Spackman 2000)和统一医学语言系统的语义网络(Humphreys and Lindberg 1993)。广泛的通用本体也正在兴起。例如, 联合国开发计划署和Dun&Bradstreet共同努力开发UNSPSC本体,该本体提供产品和服务的术语(www.unspsc.org)。
本体为需要在域中共享信息的研究人员定义了通用词汇表。它包括领域中基本概念的机器可解释的定义以及它们之间的关系。
为什么有人要开发一个本体?一些原因是:
· 在人员或软件代理之间共享对信息结构的共识
· 能够重用领域知识
· 明确领域假设
· 将领域知识与运营知识区分开
· 分析领域知识
在人员或软件代理之间共享对信息结构的 共识是开发本体论的较常见目标之一(Musen 1992; Gruber 1993)。例如,假设几个不同的网站包含医疗信息或提供医疗电子商务服务。如果这些网站共享并发布它们全部使用的术语的相同基础本体,则计算机代理可以从这些不同的网站中提取和聚合信息。代理可以使用此汇总信息来回答用户查询或作为其他应用程序的输入数据。
启用领域知识的重用是最近本体论研究激增的推动力之一。例如,用于许多不同领域的模型需要表示时间的概念。此表示包括时间间隔,时间点,时间的相对度量等概念。如果一组研究人员详细开发了这种本体,那么其他研究人员可以简单地将其重新用于他们的领域。此外,如果我们需要构建大型本体,则可以集成描述大型域各部分的几种现有本体。我们还可以重用通用的本体,例如UNSPSC本体,并将其扩展以描述我们感兴趣的领域。
如果我们对领域的了解有所变化,则对实现的基础进行明确的领域假设就可以轻松更改这些假设。关于编程语言世界的硬编码假设使这些假设不仅难以发现和理解,而且难以更改,特别是对于没有编程专业知识的人。此外,明确的领域知识规范对于必须了解领域术语含义的新用户很有用。
将领域知识与操作知识分开是本体的另一种常见用法。我们可以描述根据所需规范从其组件配置产品的任务,并实现一个独立于产品和组件本身进行配置的程序(McGuinness和Wright 1998)。然后,我们可以开发PC组件和特性的本体,并应用该算法来配置定制PC。如果我们将电梯组件本体“馈入”到电梯中,我们也可以使用相同的算法来配置电梯(Rothenfluh et al。1996)。
一旦可以使用术语的声明性规范,就可以分析领域知识。 当试图重用现有本体并扩展它们时,术语的形式分析非常有价值(McGuinness et al。2000)。
通常,领域的本体本身并不是目标。开发本体类似于定义一组数据及其结构以供其他程序使用。解决问题的方法,与领域无关的应用程序和软件代理使用从本体构建的本体和知识库作为数据。例如,在本文中,我们开发了葡萄酒和食物的本体以及葡萄酒和餐食的适当组合。然后,可以将此本体用作一套餐厅管理工具中某些应用程序的基础:一个应用程序可以为当天的菜单创建葡萄酒建议或回答服务员和顾客的查询。另一个应用程序可以分析酒窖的库存清单,并建议扩展哪些酒类别以及为即将来临的菜单或菜谱购买哪些特定酒。
关于本指南
我们基于Protégé-2000 (Protege 2000),Ontolingua (Ontolingua 1997),Chimaera (Chimaera 2000)作为本体编辑环境的经验。在本指南中,我们以Protégé-2000为例。
我们在本指南中始终使用的葡萄酒和食品示例大致基于本文中描述CLASSIC的示例知识库,该知识库是一种基于描述逻辑方法的知识表示系统(Brachman等,1991)。CLASSIC教程(McGuinness等,1994)进一步开发了此示例。Protégé-2000和其他基于框架的系统以声明方式描述了本体,并明确说明了类层次结构以及个人所属的类。
本指南中的一些本体设计思想源于有关面向对象设计的文献(Rumbaugh等,1991; Booch等,1997)。但是,本体开发不同于面向对象程序设计中的类和关系设计。面向对象的程序设计主要围绕类的方法—程序员根据类的操作属性进行设计决策,而本体设计者则根据类的结构属性进行决策。结果,本体中的类结构和类之间的关系不同于面向对象程序中类似域的结构。
无法涵盖本体开发人员可能需要解决的所有问题,因此我们在本指南中并未尝试解决所有这些问题。相反,我们试图提供一个起点。可以帮助新的本体设计者开发本体的初始指南。最后,如果领域需要它们,我们建议地方寻找对更复杂的结构和设计机制的解释。
最后,没有一种正确的本体设计方法,我们也没有尝试定义一种方法。我们在这里提出的想法是在我们自己的本体开发经验中发现有用的想法。在本指南的最后,我们建议了替代方法的参考文献列表。
2. 什么是本体?
人工智能文献包含本体的许多定义。其中许多相互矛盾。在本指南中,本体是对话语领域(类(有时称为概念))中的概念的正式显式描述,每个概念的属性描述了概念的各种特征和属性(插槽 (有时称为角色或属性) )以及对插槽的限制(构面(有时也称为角色限制))。本体与一组单独的类实例一起构成一个知识库。实际上,存在一条直线,本体在此终止,知识库在此开始。
类是大多数本体的重点。类描述领域中的概念。例如,一类葡萄酒代表所有葡萄酒。特定的葡萄酒是此类的实例。阅读本文档时,杯中 的波尔多葡萄酒是波尔多葡萄酒类别的一个实例。一个类可以具有表示比超类更具体的概念的子类。例如,我们可以将所有葡萄酒的类别划分为红,白和桃红葡萄酒。另外,我们可以将所有葡萄酒分为起泡酒和非起泡酒。
槽口描述了类和实例的属性: 拉菲堡罗斯柴尔德波雅克酒具有完整的酒体;它由拉菲酒庄(ChâteauLafite Rothschild)酒庄生产。在此示例中,我们有两个描述葡萄酒的位置:具有完整值的位置主体和具有ChâteauLafite Rothschild酒庄价值的位置制造商。在类级别,我们可以说,Wine类的实例 将具有描述其风味, 酒体, 糖 水平, 葡萄酒制造商等的位置。[1]
Wine类及其子类Pauillac的所有实例都有一个老虎机制造商, 其值是Winery类的一个实例(图1)。Winery类的所有实例都有一个插槽产品 ,该插槽引用了该酿酒厂生产的所有葡萄酒(Wine及其子类的实例)。
实际上,开发本体包括:
· 在本体中定义类,
· 以分类(子类-超类)层次结构安排类,
· 定义插槽并描述这些插槽的允许值,
· 填写实例的插槽值。
然后,我们可以通过定义这些类的各个实例来创建知识库,以填充特定的插槽值信息和其他插槽限制。
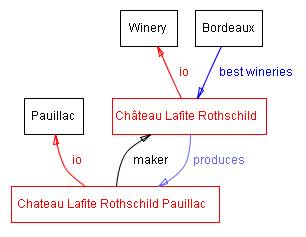 |
图1。 葡萄酒领域中的某些类,实例以及它们之间的关系。 我们将黑色用于类,将红色用于实例。直接链接表示插槽和内部链接,例如instance-of和subclass-of。
3. 一种简单的知识工程方法
正如我们之前所说,没有一种“正确”的方法或方法来开发本体。在这里,我们讨论要考虑的一般问题,并提供了一种开发本体的可能过程。我们描述了一种用于本体开发的迭代方法:我们从对本体的初步了解开始。然后,我们修改和完善不断发展的本体,并填写详细信息。在此过程中,我们讨论了设计师需要做出的建模决策,以及不同解决方案的利弊。
首先,我们要强调本体设计中的一些基本规则,我们将多次参考这些规则。这些规则似乎很教条。但是,它们可以在许多情况下帮助您做出设计决策。
1) 没有一种正确的域建模方法-总是有可行的替代方案。最佳解决方案几乎总是取决于您所考虑的应用程序和预期的扩展。
2) 本体开发必然是一个迭代过程。
3) 本体中的概念应该与您感兴趣的领域中的对象(物理或逻辑)和关系紧密相关。这些最有可能是描述您的域的句子中的名词(宾语)或动词(关系)。
也就是说,决定我们将使用本体做什么以及本体将要多么详细或通用将指导许多建模决策。在几种可行的替代方案中,我们将需要确定哪种方案更适合计划的任务,更直观,更可扩展且更易于维护。我们还需要记住,本体是世界现实的模型,本体中的概念必须反映这一现实。在定义了本体的初始版本之后,我们可以通过在应用程序或解决问题的方法中使用它或与本领域的专家进行讨论,或者同时使用两者来评估和调试它。结果,我们几乎肯定会需要修改初始本体。
步骤1. 确定本体的范围和范围
我们建议通过定义领域和范围来开始开发本体。也就是说,回答几个基本问题:
· 本体将涵盖的领域是什么?
· 对于 我们将使用本体的东西?
· 对于哪种类型的问题,本体中的信息应提供答案?
· 谁将使用和维护本体?
这些问题的答案可能会在本体设计过程中发生变化,但是在任何给定的时间,它们都有助于限制模型的范围。
考虑一下我们前面介绍的葡萄酒和食物的本体。食物和葡萄酒的表示是本体论的领域。我们计划将此本体用于建议葡萄酒和食品良好搭配的应用程序。
自然地,描述葡萄酒的不同类型,主要食物类型,葡萄酒与食物的良好组合以及不良组合的概念将成为我们的本体。同时,本体不大可能包含用于管理酒厂或饭店员工库存的概念,即使这些概念在某种程度上与葡萄酒和食物的概念相关。
如果我们正在设计的本体将用于协助葡萄酒杂志中文章的自然语言处理,则在本体中包含概念的同义词和词性信息可能很重要。如果本体将用于帮助餐厅顾客决定订购哪种酒,我们需要包括零售价格信息。 如果将其用于购酒者的酒窖储藏,可能需要批发价格和供货情况。 如果维护本体的人员使用与本体用户所用语言不同的语言来描述域,则可能需要提供这些语言之间的映射。
能力问题。
确定本体论范围的一种方法是勾勒出基于本体论的知识库应该能够回答的一系列问题,即能力问题 (Gruninger和Fox 1995)。这些问题将在稍后用作石蕊测试:本体是否包含足够的信息来回答这些类型的问题?答案是否需要特定级别的详细信息或特定区域的表示形式?这些能力问题仅是一个草图,不需要详尽。
在葡萄酒和食品领域,以下是可能的能力问题:
· 选择葡萄酒时应考虑哪些葡萄酒特性?
· 波尔多是红葡萄酒还是白葡萄酒?
· 赤霞珠与海鲜搭配得很好吗?
· 烤肉用葡萄酒的最佳选择是什么?
· 葡萄酒的哪些特性会影响其对菜肴的适合性?
· 特定年份的酒香或酒体会随着年份的变化而变化吗?
· 纳帕仙粉黛的最佳年份是什么?
从这个问题列表中判断,本体将包括有关各种葡萄酒特性和葡萄酒类型,年份(好坏)的信息,这些葡萄酒的分类对选择合适的葡萄酒至关重要,推荐的葡萄酒和食物组合。
步骤2. 考虑重用现有的本体
几乎总是值得考虑别人做了什么,并检查我们是否可以针对特定领域和任务优化和扩展现有资源。如果我们的系统需要与已经承诺使用特定本体或受控词汇表的其他应用程序进行交互,则可能需要重用现有本体。 许多本体已经可以电子形式获得,并且可以导入到您正在使用的本体开发环境中。表达本体的形式主义通常并不重要,因为许多知识表示系统可以导入和导出本体。即使知识表示系统不能直接用于特定形式主义,将本体从一种形式主义转换为另一种形式主义的任务通常也不是一件容易的事。
网络上和文献中都有可重用的本体库。例如,我们可以使用Ontolingua本体库(http://www.ksl.stanford.edu/software/ontolingua/)或DAML本体库(http://www.daml.org/ontologies/)。 还有许多公开可用的商业本体(例如,UNSPSC(www.unspsc.org),RosettaNet(www.rosettanet.org),DMOZ(www.dmoz.org))。
例如,法国葡萄酒的知识库可能已经存在。如果我们可以导入此知识库及其基础知识,那么我们不仅将具有法国葡萄酒的分类,而且还将获得用于区分和描述葡萄酒的葡萄酒特征分类的第一遍。葡萄酒属性列表可能已经可以从商业网站(例如www.wines.com)上获得 ,客户可以将其用于购买葡萄酒。
但是,对于本指南,我们将假定不存在相关的本体,并从头开始开发本体。
步骤3. 列举本体中的重要术语
写下所有我们希望对用户做出陈述或向用户解释的术语的列表很有用。我们想谈什么?这些条款具有哪些属性?我们想对这些条款说些什么?例如,与葡萄酒有关的重要术语将包括葡萄酒,葡萄,酿酒厂,位置,葡萄酒的颜色,酒体,风味 和糖含量;不同类型的食物,如鱼和红肉; 葡萄酒的亚型,例如白葡萄酒, 等等。最初,获得完整的术语列表很重要,而不必担心它们表示的概念之间的重叠,术语之间的关系或概念可能具有的任何属性,或者概念是类还是插槽。
接下来的两个步骤-开发类层次结构和定义概念(插槽)的属性-紧密地交织在一起。很难先做一个,然后再做另一个。通常,我们在层次结构中创建一些概念定义,然后 继续描述这些概念的属性,依此类推。这两个步骤也是 本体设计过程中最重要的步骤。我们将在这里简要描述它们,然后在接下来的两个部分中讨论需要考虑的更复杂的问题,常见的陷阱,做出的决定等等。
步骤4. 定义类和类层次结构
开发类层次结构有几种可能的方法(Uschold和Gruninger 1996):
· 一个自上而下的发展过程开始的域和的概念,随后专业化的最一般的概念的定义。例如,我们可以从创建Wine 和Food的一般概念的类开始。然后,我们 通过创建其子类来专门研究Wine类:白葡萄酒,红葡萄酒,桃红葡萄酒。我们可以将红酒类进一步分类,例如,西拉, 勃艮第红葡萄酒,赤霞珠等。
· 一个自下而上的发展过程从最具体的类别,层次结构的叶子,这些类的后续分组定义成更一般的概念。例如,我们首先定义波雅克 和玛歌 葡萄酒的类。然后,我们为这两个类(Medoc)创建一个公共超类,而该类又是Bordeaux的子类。
· 一个组合的发展过程是自上而下和自下而上的方法的组合:我们先定义了更加突出的概念推广,并适当专门它们。我们可能从一些顶级概念(例如Wine)和一些特定概念(例如Margaux)开始 。然后,我们可以将它们与诸如Medoc的中级概念相关联。 然后,我们可能想从法国生成所有区域葡萄酒类,从而生成许多中级概念。
图2 显示了不同普遍性级别之间的细分情况。
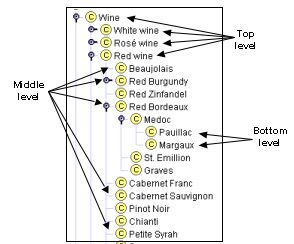 |
图2。葡萄酒 分类的不同层次:葡萄酒, 红酒,白葡萄酒,桃红葡萄酒是更一般的概念,即最高层次。波雅克(Pauillac) 和玛歌(Margaux) 是层次结构中最具体的类,即底层。
这三种方法在本质上都不比其他任何一种更好。采取的方法在很大程度上取决于域的个人观点。如果开发人员对域有系统的自顶向下视图,则使用自顶向下方法可能会更容易。对于许多本体开发者来说,组合方法通常是最简单的,因为“中间”的概念往往是该领域中更具描述性的概念(Rosch 1978)。
如果您倾向于先区分最一般的分类来考虑葡萄酒,那么自上而下的方法可能会更好。如果您希望从具体示例入手,那么自下而上的方法可能更合适。
无论选择哪种方法,我们通常都从定义类开始。从步骤3中创建的列表中,我们选择描述具有独立存在的对象的术语,而不是描述这些对象的术语。这些术语将成为本体中的类,并将成为类层次结构中的基础。[2]通过询问是否作为一个类的实例,该对象是否必然(即根据定义)是某个其他类的实例,从而将这些类组织为分层分类法。
如果类A是类B的超类,那么B的每个实例也是A的实例
换句话说,B类代表的概念是A的“一种”。
例如,每种黑比诺葡萄酒都一定是红酒。因此,黑皮诺(Pinot Noir)类是红酒类的子类。
图2 显示了Wine本体的部分层次结构。第4节 详细讨论了在定义类层次结构时要寻找的内容。
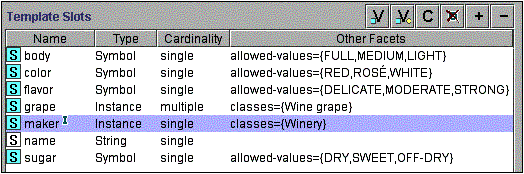 |
图3。Wine类的插槽 和这些插槽的构面。厂商 插槽旁边的“ I”图标表示该插槽具有反字符(第5.1节)
步骤5. 定义类的属性-插槽
仅这些课程将无法提供足够的信息来回答步骤1中的能力问题。一旦定义了一些类,就必须描述概念的内部结构。
我们已经从步骤3中创建的术语列表中选择了类。其余大多数术语可能是这些类的属性。这些术语包括,例如,葡萄酒的颜色,酒体,风味和糖分含量以及 酒厂的位置。
对于列表中的每个属性,我们必须确定其描述的类。这些属性成为附加到类的插槽。因此,Wine 类将具有以下位置:颜色,主体, 风味和糖。酒庄 课程将有一个位置 栏。
通常,有几种类型的对象属性可以成为本体中的插槽:
· “固有”属性,例如 葡萄酒的味道;
· “外在”性质,如酒的名字, 和区域 它来自;
· 零件(如果对象是结构化的);这些可以是物理的和抽象的“部分”(例如,一顿饭的过程)
· 与其他人的关系;这些是班级成员与其他项目之间的关系(例如, 葡萄酒制造商,代表一种葡萄酒与一个酿酒厂之间的关系,以及 该葡萄酒所用的葡萄。)
因此,除了我们之前确定的属性之外,我们还需要在Wine 类中添加以下插槽:name, area, maker, grape。 图3显示了Wine类的插槽。
一个类的所有子类都继承该类 的插槽。例如,Wine类的所有插槽 都将继承到Wine的所有子类,包括Red Wine和White Wine。我们将在红酒类中添加一个附加的单宁水平(低,中或高)。所述单宁水平槽就会由表示红葡萄酒(如所有类继承波尔多 和博若莱)。
应该在可以具有该属性的最通用类上附加一个插槽。例如, 葡萄酒类的酒体 和颜色应该附加在酒类上,因为它是最通用的类,其实例将具有酒体和颜色。
步骤6. 定义插槽的刻面
插槽可以具有描述值类型,允许的值,值的数量(基数)以及插槽可以采用的值的其他特征的不同方面。例如,名称 槽的值(如“葡萄酒的名称”)为一个字符串。也就是说,名称 是值为String的插槽。槽位生产 (如“酿酒厂生产 这些葡萄酒”)可以具有多个值,并且这些值是Wine类的实例。也就是说,产生的 是具有类型类型为实例的插槽, 并且将Wine 作为允许的类。
现在,我们将描述几个常见方面。
插槽基数
插槽基数定义一个插槽可以具有多少个值。某些系统仅区分单基数(最多允许一个值)和多基数(允许任意数量的值)。 葡萄酒的主体将是单个基数槽(葡萄酒只能具有一个主体)。通过在多基数时隙的特定酒厂填充生产的葡萄酒生产 用于酿酒厂 类。
一些系统允许指定最小和最大基数,以更精确地描述插槽值的数量。最小基数N表示插槽必须至少具有N个值。例如, 葡萄酒的葡萄槽的最小基数为1:每种葡萄酒均由至少一种葡萄制成。M的最大基数意味着一个插槽最多可以具有M个值。 单一品种葡萄酒的葡萄位的最大基数为1:这些葡萄酒仅由一种葡萄制成。有时将最大基数设置为0可能会有用。此设置将指示该插槽对于特定子类不能具有任何值。
广告位值类型
值类型构面描述了可以在插槽中填充哪些类型的值。这是更常见的值类型的列表:
· 字符串是用于诸如名称之类的插槽的最简单的值类型:该值是一个简单的字符串
· 数字(有时使用更具体的值类型为Float和Integer)描述带有数字值的插槽。例如, 葡萄酒的价格可以具有值类型Float
· 布尔槽是简单的yes – no标志。例如,如果我们选择不将起泡葡萄酒表示为单独的类,则可以将葡萄酒是否起泡表示为布尔值插槽的值:如果该值为“ true”(“是”),则该葡萄酒正在起泡如果值为“ false”(“否”),则该葡萄酒不是气泡酒。
· 枚举槽指定了槽的特定允许值的列表。例如,我们可以指定风味 插槽可以采用以下三种可能的值之一:强, 中度和精致。在Protégé-2000中,枚举插槽的类型为Symbol。
· 实例类型插槽允许定义个人之间的关系。值类型为Instance的插槽还必须定义实例可以来自的允许类的列表。例如, 为Winery类产生的广告位 可以将Wine类的实例 作为其值。[3]
图4显示了Winery 类上的插槽产品的定义。
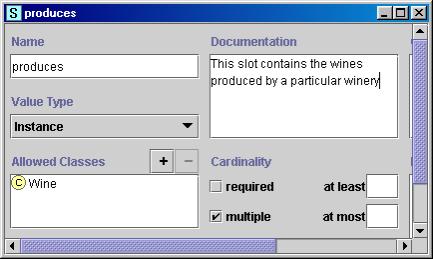 |
图4。插槽产品的定义 描述了酒厂生产的葡萄酒。插槽的基数倍数,值类型为Instance,并且类Wine 为值的允许类。
插槽的域和范围
实例类型的插槽的允许类通常称为插槽范围。在图4的示例中 ,Wine类 是Produces 广告位的范围。当为特定类别连接插槽时,某些系统允许限制插槽的范围。
插槽所属的类或插槽描述的属性的类称为插槽的域。在酒厂 类是的域产生 槽。在将插槽附加到类的系统中,插槽所附加的类通常构成该插槽的域。无需单独指定域。
确定插槽的域和范围的基本规则相似:
在定义插槽的域或范围时,找到最通用的类或可以分别是插槽的域或范围的类。
另一方面,请勿定义过于笼统的域和范围:插槽的域中的所有类均应由插槽描述,并且插槽范围内的所有类的实例应为插槽。范围过于笼统的类(即,一个不想使范围为THING的类),但是想要选择一个覆盖所有填充物的类
而不是列出Produces 插槽 范围内Wine类的所有可能子类,只需列出Wine即可。同时,我们不想将插槽的范围指定为THING(本体中最通用的类)。
具体来说:
如果定义 插槽范围或域的类列表中包括一个类及其子类,请删除该子类。
如果槽的范围包含两个葡萄酒 类和红酒类,我们可以去除红葡萄酒从范围,因为它没有添加任何新的信息:红葡萄酒是一个子类葡萄酒 ,因此插槽范围已经隐含包括它以及Wine 类的所有其他子类。
如果定义 插槽范围或域的类列表包含类A的所有子类,但不包含类A本身,则范围应仅包含类A,而不包含子类。
无需定义插槽的范围包括红葡萄酒,白葡萄酒和桃红葡萄酒(列举的所有直接子类酒),我们可以限制的范围内对类酒 本身。
如果定义 插槽范围或范围的类的列表包含A类的少数几个子类,则请考虑A类是否会做出更 合适的范围定义。
在将插槽附加到类与将类添加到插槽的域相同的系统中,相同的规则适用于插槽附加:一方面,我们应尝试使其尽可能通用。另一方面,我们必须确保插槽所连接的每个类都可以确实具有插槽所代表的属性。我们可以将单宁水平槽附加到代表红酒的每个类别上(例如,波尔多, 梅洛, 博若莱等)。但是,由于所有红酒都具有单宁水平,因此我们应该将插槽添加到此类更通用的红酒中。一般化的域单宁平 由于我们不使用单宁水平来描述白葡萄酒,因此进一步扩展(通过将其附加到Wine类)是不正确的。
步骤7. 创建实例
最后一步是在层次结构中创建类的各个实例。定义一个类的单个实例需要(1)选择一个类,(2)创建该类的单个实例,以及(3)填写广告位值。例如,我们可以创建一个单独的Chateau-Morgon-Beaujolais实例 来代表特定类型的博若莱葡萄酒。 夏上海摩根-博若莱是类的实例薄酒 代表所有的博若莱葡萄酒。该实例定义了以下插槽值(图5):
· 机身: 轻盈
· 颜色: 红色
· 口味: 精致
· 单宁水平:低
· 葡萄: 佳美(酿酒葡萄类别的实例)
· 制造商:Chateau-Morgon(酒庄 级别的实例)
· 地区: 博若莱(葡萄酒区域 类别的实例)
· 糖: 干
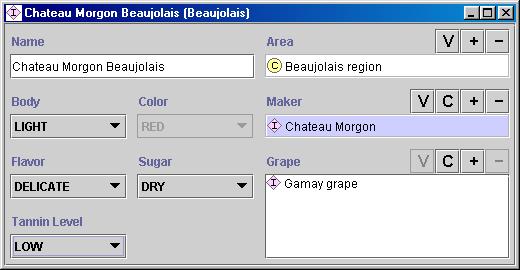 |
图5。博若莱 类的实例的定义。实例是来自博若莱地区的Chateua Morgon博若莱酒,它是由莫贡城堡酒庄的佳美葡萄酿制而成。酒体清淡,香气细腻,红色,单宁含量低。这是干酒。
4. 定义类和类层次
本节讨论的事情看出来的和定义类和类层次结构(何时进行,很容易错误的步骤4,从第3节)。如前所述,对于任何给定的域,没有单个正确的类层次结构。层次结构取决于本体的可能用途,应用程序必需的详细程度,个人喜好,有时还要求与其他模型兼容。但是,我们讨论了开发类层次结构时要牢记的几条准则。定义了大量新类后,退后一步检查新兴层次结构是否符合这些准则将很有帮助。
4.1 确保类层次结构正确
“是”关系
类层次结构表示“ is-a”关系:如果B的每个实例也是A的实例,则类A是B的子类。例如,霞多丽 是White wine的子类。认为生物分类关系的另一种方式是“种”关系:霞多丽 是一种白葡萄酒。喷气客机是一种飞机。肉是一种食物。
类的子类表示一个概念,该概念是超类表示的概念的“种类”。
单一的葡萄酒不是所有葡萄酒的子类
常见的建模错误是在层次结构中包含相同概念的单数形式和复数形式,从而使前者成为后者的子类。例如,它是错误的定义类葡萄酒 和一类葡萄酒 作为一个子类葡萄酒。一旦您将层次结构视为代表“某种”关系,就可以清楚地看出建模错误:单个Wine 并不是一种 Wines。避免此类错误的最佳方法始终是在命名类中使用单数或复数(有关命名概念的讨论,请参见第6节)。
等级关系的可及性
子类关系是可传递的:
如果B是A的子类并且C是B的子类,则C是A的子类
例如,我们可以定义一个Wine类,然后将一个White wine类定义为Wine的子类。然后,我们将霞多丽 类别定义为白葡萄酒的子类别。子类关系的及物性意味着霞多丽 类也是Wine的子类。有时我们区分直接子类和间接子类。一个直接的子类是类的“最近的”子类:有一类和层次结构的直接子类之间没有阶级。也就是说,在一个类及其直接超类之间的层次结构中没有其他类。在我们的示例中,霞多丽 是的直接子类白葡萄酒,而不是直接的子类酒。
类层次结构的演变
随着领域的发展,保持一致的类层次结构可能会变得充满挑战。例如,多年来,所有仙粉黛葡萄酒都是红色的。因此,我们将一类金粉黛 葡萄酒定义为红葡萄酒类的子类。但是,有时酿酒师开始压榨葡萄,并立即去除葡萄的颜色产生部分,从而改变了所得葡萄酒的颜色。因此,我们得到颜色为玫瑰色的“白色仙粉黛”。现在,我们需要将“仙粉黛” 类分为两类仙粉黛:白仙粉黛和红仙粉黛,并将它们分别分类为玫瑰酒和红酒的子类。
类及其名称
区分类及其名称很重要:
类代表领域中的概念,而不是代表这些概念的词。
如果我们选择不同的术语,则类别的名称可能会更改,但是该术语本身代表着世界上的客观现实。例如,我们可以创建一个Shrimps类,然后将其重命名为Prawns-该类仍表示相同的概念。指虾菜肴的适当葡萄酒组合应指对虾菜肴。实际上,应始终遵循以下规则:
相同概念的同义词不代表不同的类别
同义词只是概念或术语的不同名称。因此,我们应该不会有一类叫做虾 和被称为类虾,以及可能称为类Crevette。而是有一个类,名为Shrimp 或Prawn。许多系统允许将同义词, 翻译或表示名称的列表与类相关联。如果系统不允许这种关联,则可以始终在类文档中列出同义词。
避免上课周期
我们应该避免类层次结构中的循环。我们说,当某个类A具有子类B并且同时B是A的超类时,在层次结构中存在一个循环。在层次结构中创建这样的循环等于声明类A和B是等效的:全部A的实例是B的实例,B的所有实例也是A的实例。确实,由于B是A的子类,所以所有B的实例都必须是A类的实例。由于A是B的子类,所以所有A的实例也必须是B类的实例。
4.2 分析类层次结构中的同级
类层次结构中的兄弟姐妹
兄弟姐妹在层次是属于同一类的直接子类类(参见第4.1)。
层次结构中的所有兄弟姐妹(除了根节点的兄弟姐妹)都必须处于相同的通用级别。
例如,白葡萄酒和霞多丽 不应该是同一类的子类(例如Wine)。 白酒比霞多丽更普遍。兄弟姐妹应该代表“沿着同一线”的概念,就像 书中相同级别的部分具有相同的一般性。从这个意义上讲,对类层次结构的要求类似于对书本大纲的要求。
但是,位于层次结构根部的概念(通常表示为某些非常通用的类的直接子类,例如Thing)表示域的主要划分,而不必是相似的概念。
多少是太多?
对于一个类应具有的直接子类数目,没有硬性规定。但是,许多结构良好的本体具有两个到十二个直接子类。因此,以下两个准则:
如果一个类只有一个直接子类,则可能存在建模问题或本体不完整。
如果给定类的子类超过十二个,则可能需要其他中间类。
这两个规则中的第一个类似于排版规则,即项目符号列表永远不应只有一个项目符号点。例如,大多数勃艮第红葡萄酒都是科特迪瓦(Côtesd’Or)葡萄酒。假设我们只想代表大多数这种勃艮第葡萄酒。我们可以创建一个类干红葡萄酒,然后一个子类柯特斯d’Or的(图6一)。但是,如果在我们的代理中,勃艮第红色和科多尔葡萄酒基本相同(所有勃艮第红色葡萄酒都是科多尔葡萄酒,而科多尔所有葡萄酒都是勃艮第红色葡萄酒),则可以创建科特迪瓦类不是必需的,并且不会向表示形式添加任何新信息。如果我们包括阿摩尔Chalonnaise葡萄酒,这是该地区更便宜的勃艮第葡萄酒正南阿摩尔d’Or的,那么我们将创建的两个子类勃艮第 类:柯特斯d’Or酒店和科茨Chalonnaise(图6 b)。
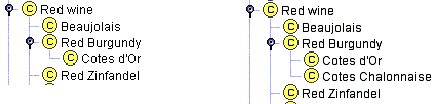 |
图6。红色勃艮第类的子类。一个类只有一个子类通常会指出建模中的问题。
现在假设我们将所有类型的葡萄酒都列为Wine 类的直接子类。然后,该列表将包括这样的更一般类型的酒作为博若莱和波尔多,以及更具体的类型,如Paulliac和玛(图7一个)。Wine类 有太多直接的子类,而且,为了使本体论能够以更有条理的方式反映不同类型的葡萄酒,Medoc 应该是波尔多的子类, 而Cotes d’Or应该是勃艮第的子类。还具有红酒和白葡萄酒等中间类别这也将反映出许多人拥有的葡萄酒领域的概念模型(图7b)。
但是,如果不存在自然类来将一长串同胞中的概念归为一组,则无需创建人工类-只需按原样保留类即可。毕竟,本体是对现实世界的反映,如果在现实世界中不存在任何分类,则本体应该反映出来。
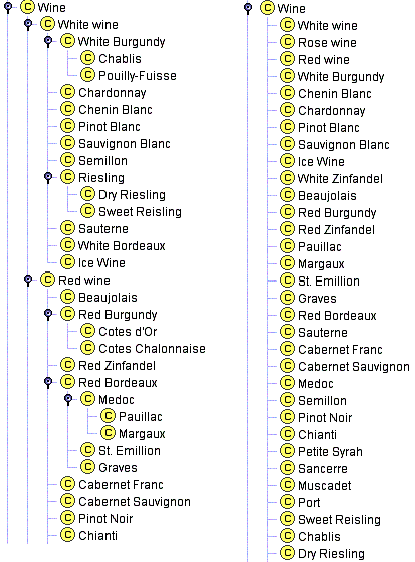 |
图7。对葡萄酒进行分类。具有所有葡萄酒和葡萄酒类型,而不具有多个分类级别。
4.3 多重继承
大多数知识表示系统都允许在类层次结构中进行多重继承:一个类可以是多个类的子类。假设我们要创建一个单独的甜品酒类,即甜品酒类。波特酒既是红酒又是甜品酒。[4] 因此,我们将Port类定义 为具有两个超类:Red wine和Dessert wine。Port 类的所有实例都将是Red Wine类和Dessert wine类的实例。该端口 班级将从其父母双方那里继承其广告位及其方面。因此,将继承该插槽的值SWEET糖 从甜酒类和单宁水平槽和用于从它的色彩时隙的值红酒类。
4.4 何时开设新课程(或不开设)
在建模期间做出的最困难的决定之一是何时引入新类或何时通过不同的属性值表示区别。很难浏览具有许多无关类的极其嵌套的层次结构和非常平坦的层次结构,该层次结构的类太少,在插槽中编码的信息太多。要找到合适的平衡并不容易。
有几条经验法则可以帮助您决定何时在层次结构中引入新类。
一个类的子类通常(1)具有超类没有的其他属性 ,或者(2)与超类不同的限制,或者(3)参与与超类不同的关系
红酒可以具有不同水平的单宁,而此属性通常不用于描述葡萄酒。甜品酒的糖槽值是SWEET,而甜品酒的超类不是。黑比诺葡萄酒可能与海鲜搭配得很好,而其他红酒则不能。换句话说,通常只有在我们可以说一些关于该类的东西而我们不能说到超类的东西时,才在层次结构中引入一个新类。
实际上,每个子类都应该添加新的插槽,或者定义新的插槽值,或者为继承的插槽覆盖某些方面。
但是,有时即使没有引入任何新属性,创建新类还是有用的。
术语层次结构中的类不必引入新的属性
例如,某些本体包括领域中使用的常用术语的大型参考层次结构。例如,电子病历系统下的本体可以包括各种疾病的分类。这种分类可能就是这样-术语的层次结构,没有属性(或具有相同的属性集)。在这种情况下,将术语组织为层次结构而不是统一列表仍然很有用,因为它将(1)允许更轻松地进行探索和导航,以及(2)使医生能够轻松地选择术语的通用级别,即适合这种情况。
引入没有任何新属性的新类的另一个原因是对概念建模,领域专家通常会在其中进行区分,即使我们可能决定不对区分本身进行建模。由于我们使用本体来促进领域专家之间以及领域专家和基于知识的系统之间的通信,因此我们希望在本体中反映专家对领域的看法。
最后,我们不应该为每个附加限制创建类的子类。 例如,我们引入了红葡萄酒,白葡萄酒和玫瑰葡萄酒两类, 因为这种区别在葡萄酒界是很自然的。我们没有介绍 精致葡萄酒,中度葡萄酒等的课程。在定义类层次结构时,我们的目标是在创建对类组织有用的新类和创建太多类之间取得平衡。
4.5 一个新的类或属性值?
在为领域建模时,我们经常需要决定是否将特定的区别(例如白葡萄酒,红葡萄酒或桃红葡萄酒)建模为属性值或一组类,这再次取决于领域的范围和手头的任务。
是创建类白葡萄酒还是简单地创建类Wine 并为广告位颜色填充不同的值?答案通常在我们为本体定义的范围内。白葡萄酒的概念有多重要在我们的域中?如果葡萄酒在该领域中仅具有很小的重要性,并且该葡萄酒是否为白葡萄酒对其与其他物品的关系没有任何特别的暗示,那么我们就不应该为白葡萄酒引入单独的类别。对于工厂生产酒标的领域模型,任何颜色的酒标的规则都是相同的,区别也不是很重要。另外,对于葡萄酒,食物及其适当的组合,红酒与白葡萄酒的区别很大:它与不同的食物搭配,具有不同的特性,依此类推。同样,酒的颜色对于我们可以用来确定品酒顺序的酒知识基础也很重要。 因此,我们为白葡萄酒创建了一个单独的类。
如果具有不同插槽值的概念成为其他类中不同插槽的限制,那么我们应该为该区别创建一个新类。否则,我们以广告位值表示区别。
同样,我们的葡萄酒本体具有Red Merlot和White Merlot之类的类别,而不是所有Merlot葡萄酒的单一类别:Red Merlots和White Merlots确实是不同的葡萄酒(由相同的葡萄制成),并且如果我们正在开发葡萄酒,这种区别很重要。
如果区分在领域中很重要,并且我们将具有不同值的对象视为不同种类的对象, 则应该为该区分创建一个新类。
考虑类的潜在个体实例也可能有助于决定是否引入新类。
单个实例所属的类不应经常更改。
通常,当我们使用概念的外在属性而不是内在属性来区分类时,这些类的实例通常必须从一个类迁移到另一个类。例如,冷冻酒不应该是描述餐厅酒瓶的本体中的一类。该性质C hilled 应该仅仅是葡萄酒在瓶中的一个属性,因为实例冷藏的葡萄酒可以轻松地停止作为这个类的一个实例,然后再次成为这个类的一个实例。
通常,数字,颜色,位置是插槽值,并且不会导致创建新类。然而,酒是一个明显的例外,因为酒的颜色对酒的描述至为重要。
再举一个例子,考虑人体解剖学本体。当我们代表肋骨时,是否为“第一个左肋骨”,“第二个左肋骨”等等创建一个类?还是我们有一个带肋的类肋骨,用于排列顺序和横向位置(左右)?[5]如果我们在本体中表示的关于每个肋骨的信息明显不同,那么我们确实应该为每个肋骨创建一个类。也就是说,如果我们要表示详细的邻接关系和位置信息(每个肋骨都不同)以及每个肋骨playa和它保护的器官的特定功能,我们需要这些类。如果我们以稍低的一般性水平对解剖模型进行建模,并且就我们的潜在应用而言,所有肋骨都非常相似(我们只是在X射线上谈论哪根肋骨断裂,而不会影响身体的其他部位) ,我们可能想简化层次结构,只使用Rib类,其中有两个位置:横向位置,顺序。
4.6 实例还是类?
确定特定概念是本体中的类还是单个实例取决于本体的潜在应用范围。确定类从何处结束和各个实例开始的地方,首先要确定表示形式中最低的粒度级别。粒度级别又由本体的潜在应用确定。换句话说,知识库中最具体的项目是什么?回到我们 在第3节第1步中确定的能力问题,构成这些问题答案的最具体概念是知识库中各个人的很好的候选人。
个体实例是知识库中最具体的概念。
例如,如果我们仅谈论将葡萄酒与食物搭配,我们将对特定的葡萄酒瓶不感兴趣。因此,诸如Sterling Vineyards Merlot之类的术语可能会成为我们使用的最具体的术语。因此,Sterling Vineyards Merlot将成为知识库中的一个实例。
另一方面,如果我们除了要保持良好的葡萄酒与食物搭配的知识基础之外,还希望在餐厅中保持葡萄酒的库存,则每种葡萄酒的单个瓶子都可能成为我们知识库中的单个实例。
同样,如果我们想为斯特林葡萄园梅洛葡萄酒的每个特定年份记录不同的属性,则该葡萄酒的特定年份是知识库中的一个实例,而斯特林葡萄园梅洛葡萄酒是一个包含所有年份的实例的类。
另一个规则可以将某些个体实例“移动”到类集中:
如果概念形成自然的层次结构,那么我们应该将它们表示为类
考虑葡萄酒产区。最初,我们可以将主要葡萄酒产区(例如法国,美国,德国等)定义为类别,并在这些大区域内定义特定的葡萄酒产区作为实例。例如,勃艮第地区是法国地区类别的一个实例。但是,我们还要说的是科特迪瓦地区是勃艮第地区。因此,勃艮第大区必须是一个类(为了具有子类或实例)。然而,使勃艮第地区的一类和阿摩尔滨海省或地区的实例勃艮第地区似乎是任意的:很难清楚地区分哪些区域是类,哪些是实例。因此,我们将所有葡萄酒产区定义为类。Protégé-2000允许用户将某些类指定为Abstract,表示该类不能具有任何直接实例。在我们的例子中,所有区域类都是抽象的(图8)。
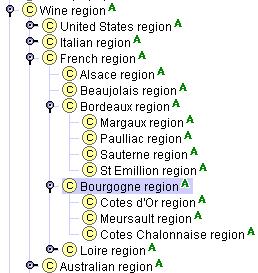 |
图8。葡萄酒产区的层次结构。类名旁边的“ A”图标表示这些类是抽象的,不能有任何直接实例。
如果我们从类名称中省略单词“ region”,则相同的类层次结构将是不正确的。我们不能说阿尔萨斯阶级 是法国阶级的子类:阿尔萨斯不是法国的一种。但是,阿尔萨斯地区是法国的一种地区。
只能将类安排在层次结构中-知识表示系统没有子实例的概念。因此,如果术语之间存在自然的层次结构,例如在第4.2节中的术语层次结构中,即使它们本身没有任何实例,也应将这些术语定义为类。
4.7 限制范围
作为定义类层次结构的最后注解,以下规则集始终有助于确定何时完成本体定义:
本体不应包含有关该域的所有可能的信息:您不需要专门化(或泛化)超过应用程序所需的内容(每种方式最多可以多一层)。
对于我们的葡萄酒和食物示例,我们不需要知道标签使用哪种纸或如何烹饪虾类。
同样,本体不应包含层次结构中所有可能的属性以及类之间的区别。
在我们的本体中,我们当然没有包括葡萄酒或食物可能具有的所有属性。 我们代表了本体中项目类别最显着的特性。 尽管葡萄酒书籍可以告诉我们葡萄的大小,但我们并未包括这些知识。 同样,我们也没有在系统中的所有术语之间添加可以想象的所有关系。 例如,我们在本体中没有包括诸如喜欢的葡萄酒和喜欢的食物之类的关系,只是为了更完整地表示我们定义的术语之间的所有相互联系。
最后一条规则也适用于在我们已经包含在本体中的概念之间建立关系。考虑描述生物学实验的本体。本体将可能包含生物有机体的概念。它还将包含实验者 执行实验的概念(带有他的名字,隶属关系等)。的确,作为一个人,实验者也恰巧是生物体。但是,我们可能不应该在本体中包含这种区别:出于这种表示的目的,实验者不是生物体,我们可能永远不会对实验者本身进行实验。如果我们代表了一切,我们可以说的关于本体中的类的话,实验者 将成为生物有机体的一个子类。但是,对于可预见的应用程序,我们不需要包括此知识。实际上,在现有类别中包括此类附加分类实际上会造成伤害:现在,实验人员的实例将具有与 生物体有关的重量,年龄,物种和其他数据的空位,但与描述实验的上下文绝对无关。但是,我们应该将此类设计决策记录在文档中,以使那些正在关注该本体并且可能不了解我们所考虑的应用程序的用户受益。
4.8 不相交的子类
许多系统允许我们明确指定几个类是不相交的。如果类不能有任何共同的实例,则它们是不相交的。例如,我们本体中的甜品酒和白酒 类并非脱节:有很多酒是两者的实例。Sweet Riesling类的Rothermel Trochenbierenauslese Riesling实例就是这样的一个例子。同时,红葡萄酒和白葡萄酒是互不相干的:没有一种葡萄酒可以同时具有红白两色。指定类是不相交的 使系统能够更好地验证本体。如果我们声明红葡萄酒和白葡萄酒类是不相交的,然后创建一个类,该类是雷司令 (白葡萄酒的子类)和波特 (红葡萄酒的子类)的子类,则系统可以指出建模错误。
5. 定义属性-更多详细信息
在本节中,我们讨论在定义本体中的插槽时要牢记的其他一些细节(第3节中的步骤5和步骤6)。我们主要讨论反向时隙和时隙的默认值。
5.1 反槽
一个时隙的值可以取决于另一个时隙的值。例如,如果一个 葡萄酒 是通过产生一个酒厂,则酒厂 产生 该葡萄酒。制造商 和生产商这两个关系称为逆关系。“双向存储”信息是多余的。当我们知道某酒厂生产葡萄酒时,使用知识库的应用程序总是可以推断出该酒厂生产该酒的逆关系的价值。但是,从知识获取的角度来看,使这两条信息明确可用很方便。这种方法允许用户在一种情况下填写葡萄酒,而在另一种情况下填写酒庄。然后,知识获取系统可以自动填写逆关系的值,以确保知识库的一致性。
我们的例子中有一个对 逆槽:该制造商 的的槽葡萄酒 类和产生 所述的槽酒厂 类。当用户创建Wine 类的实例并填写maker 插槽的值时,系统会自动将新创建的实例添加到 相应Winery 实例的Produces插槽。例如,当我们说Sterling Merlot由Sterling Vineyard酿酒厂生产时,系统会自动将Sterling Merlot添加到Sterling Vineyard酿酒厂生产的葡萄酒清单中。(图9)。
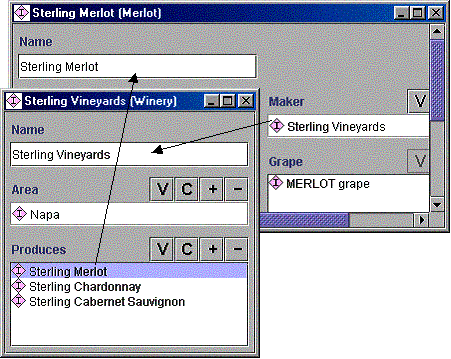 |
图9。具有反槽的实例。槽产生 的类酒厂 是槽的逆制造者 为类葡萄酒。填充其中一个插槽会触发另一个插槽的自动更新。
5.2 默认值
许多基于帧的系统都允许指定插槽的默认值。 如果某个类的大多数实例的特定插槽值都相同,则可以将该值定义为该 插槽的默认 值。然后,在创建包含该插槽的类的每个新实例时,系统会自动填写默认值。然后,我们可以将值更改为构面允许的任何其他值。也就是说,这里有默认值是为了方便:它们不会对模型施加任何新限制或以任何方式更改模型。
例如,如果我们将要讨论的大多数葡萄酒是浓郁的葡萄酒,那么我们可以将“浓郁”作为葡萄酒的默认值。然后,除非另有说明,否则我们定义的所有葡萄酒都将是浓郁的。
请注意,这与 插槽值不同。插槽值不能更改。例如, 对于甜品酒类,可以说槽糖的价值为SWEET 。然后,甜酒类的所有子类和实例都将具有槽糖的SWEET值。在任何子类或类实例中都不能更改此值。
6. 名字叫什么?
为本体中的概念定义命名约定,然后严格遵守这些约定,不仅使本体更易于理解,而且还有助于避免一些常见的建模错误。命名概念有很多选择。通常,没有特别的理由选择一个或另一种选择。但是,我们需要
定义类和插槽的命名约定并遵守。
知识表示系统的以下功能会影响命名约定的选择:
· 系统是否为类,插槽和实例使用相同的名称空间?也就是说,系统是否允许具有相同名称的类和槽位(例如类酒厂 和槽位酒厂)?
· 系统区分大小写吗?也就是说,系统是否将仅在大小写不同的名称视为不同的名称(例如Winery 和winery)?
· 系统允许在名称中使用哪些定界符?也就是说,名称可以包含空格,逗号,星号等吗?
例如,Protégé-2000为其所有框架维护一个名称空间。区分大小写。因此,我们不能拥有一流的酿酒厂 和散装酿酒厂。但是,我们可以有一个Winery类 (不是大写)和一个slot winery。另一方面,CLASSIC不区分大小写,并且为类,插槽和个人维护不同的名称空间。因此,从系统角度来看,命名类和老虎机Winery都没有问题。
6.1 大写和分隔符
首先,如果对概念名称使用一致的大写字母,则可以大大提高本体的可读性。例如,通常使用大写的类名,并使用小写字母表示插槽名称(假设系统区分大小写)。
当一个概念名称包含多个单词时(例如Meal course),我们需要对单词进行定界。这是一些可能的选择。
· 使用空间:进餐课程(许多系统,包括Protégé,都在概念名称中留有空格)。
· 一起运行单词并大写每个新单词:MealCourse
· 在名称中使用下划线或破折号或其他定界符:Meal_Course,Meal_course,Meal-Course,Meal-course。(如果使用定界符,则还需要确定每个新单词是否都大写)
如果知识表示系统允许在名称中使用空格,那么对于许多本体开发人员来说,使用它们可能是最直观的解决方案。但是,重要的是要考虑您的系统可能与之交互的其他系统。 如果这些系统不使用空格,或者您的表示媒体不能很好地处理空格,则使用另一种方法会很有用。
6.2 单数或复数
类名表示对象的集合。例如,葡萄酒 一类实际上代表了所有葡萄酒。因此,对于某些设计师而言,将类称为Wines 而不是Wine更为自然。没有其他选择比其他选择更好或更糟的(尽管在实践中经常使用类名的单数形式)。但是,无论选择什么,都应该在整个本体中保持一致。某些系统甚至要求其用户预先声明概念名称是否将使用单数或复数,并且不允许他们偏离该选择。
始终使用相同的表单还可以防止设计人员犯下诸如创建类Wines 然后创建类Wine 作为其子类的建模错误(请参见4.1节)。
6.3 前缀和后缀约定
一些知识库方法建议在名称中使用前缀和后缀约定来区分类和插槽。 两种常见的做法是增加一个人─ 或后缀-of 位名称。 因此, 如果我们选择了has- 常规,我们的老虎机将成为has-maker 和has-winery。槽成为制造商-中 和酒厂-的 ,如果我们选择了OF- 约定。这种方法允许任何查看术语的人立即确定该术语是类还是空位。但是,术语名称会稍长一些。
6.4 其他命名注意事项
定义命名约定时,还需要考虑以下几点:
· 请勿在概念名称中添加诸如“ class”,“ property”,“ slot”等字符串。
例如,从上下文中始终可以清楚地看到该概念是类还是插槽。另外,您对类和插槽使用了不同的命名约定(例如,分别使用大写和不使用大写),该名称本身将指示该概念是什么。
· 避免概念名称缩写通常是一个好主意(即,使用Cabernet Sauvignon而不是Cab)
· 类的直接子类的名称应全部包含或不包含超类的名称。例如,如果我们要创建Wine 类的两个子类来表示红葡萄酒和白葡萄酒,则这两个子类名称应该是Red Wine和White Wine或Red and White,而不是Red Wine and White。
7. 其他资源
我们将Protégé-2000用作示例的本体开发环境。Duineveld及其同事(Duineveld et al。2000) 描述并比较了许多其他本体开发环境。
我们试图解决本体开发的基础知识,并且没有讨论本体开发的许多高级主题或替代方法。Gómez-Pérez (Gómez- Pérez1998 )和Uschold (Uschold and Gruninger 1996) 提出了替代的本体开发方法论。Ontolingua教程(Farquhar,1997年)讨论了知识建模的一些形式方面。
当前,研究人员不仅强调本体的发展,还强调本体的分析。 随着更多本体的产生和重用,将有更多工具可用于分析本体。例如,Chimaera (McGuinness et al。2000) 提供了用于分析本体的诊断工具。Chimaera执行的分析既包括检查本体的逻辑正确性,也包括诊断常见的本体设计错误。本体设计者可能希望在不断发展的本体上运行Chimaera诊断,以确定与常见本体建模实践的一致性。
8. 结论
在本指南中,我们描述了基于声明性框架的系统的本体开发方法。我们列出了本体开发过程中的步骤,并解决了定义类层次结构以及类和实例的属性的复杂问题。但是,遵循所有规则和建议后,要记住的最重要的事情之一是:对于任何域,都没有单一的正确本体。本体设计是一个创造性的过程,没有两个由不同人设计的本体是相同的。本体的潜在应用以及设计者对领域的理解和看法无疑会影响本体设计的选择。“证明在布丁中” —我们只能通过在我们为其设计的应用程序中使用本体来评估本体的质量。
致谢
Protégé-2000(http://protege.stanford.edu)由Stanford Medical Informatics的Mark Musen小组开发。我们使用Protégé-2000的OntoViz插件生成了一些图形。我们从Ontolingua本体库(http://www.ksl.stanford.edu/software/ontolingua/)中导入了葡萄酒本体的初始版本,该库又使用了Brachman及其同事发布的版本(Brachman等,1991)。并随CLASSIC知识表示系统一起分发。然后,我们修改了本体,以提供基于声明性框架的本体的概念建模原则。雷·费尔格森(Ray Fergerson)和莫·佩莱格(Mor Peleg)对早期草案的广泛评论极大地改善了本文。
参考文献
Booch,G.,Rumbaugh,J。和Jacobson,I。(1997)。统一建模语言用户指南:Addison-Wesley。
Brachman,RJ,McGuinness,DL,Patel-Schneider,PF,Resnick,LA和Borgida,A。(1991)。与CLASSIC一起生活:何时以及如何使用类似KL-ONE的语言。语义网络原理。JF Sowa,摩根考夫曼(Morgan Kaufmann)编辑: 401-456。
Brickley,D.和Guha,RV(1999)。资源描述框架(RDF)架构规范。万维网联盟建议的建议: http : //www.w3.org/TR/PR-rdf-schema。
Chimaera(2000)。Chimaera本体环境。www.ksl.stanford.edu/software/chimaera
Duineveld,AJ,Stoter,R.,Weiden,MR,Kenepa,B.和Benjamins,VR(2000)。WonderTools?本体工程工具的比较研究。国际人类计算机研究杂志 52(6):1111-1133。
Farquhar,A.(1997)。Ontolingua教程。http://ksl-web.stanford.edu/people/axf/tutorial.pdf
Gómez-Pérez,A。(1998)。知识共享和重用。应用专家系统手册。利勃维茨,CRC出版社编辑。
Gruber,TR(1993)。一种可移植本体规范的翻译方法。知识获取 5:199-220。
Gruninger,M。和Fox,MS(1995)。本体设计和评估的方法论。在:知识共享中的基本本体问题研讨会的论文集,IJCAI-95,蒙特利尔。
Hendler,J。和McGuinness,DL(2000)。DARPA代理标记语言。IEEE智能系统 16(6):67-73。
Humphreys,BL和Lindberg,DAB(1993)。UMLS项目:在用户和他们所需的信息之间建立概念上的联系。医学图书馆协会公告 81(2):170。
McGuinness,DL,Abrahams,MK,Resnick,LA,Patel-Schneider,PF,Thomason,RH,Cavalli-Sforza,V.和Conati,C.(1994)。经典知识表示系统教程。http://www.bell-labs.com/project/classic/papers/ClassTut/ClassTut.html
McGuinness,DL,Fikes,R.,Rice,J。和Wilder,S。(2000)。合并和测试大型本体的环境。知识表示和推理的原理:第七届国际会议论文集(KR2000)。AG Cohn,F。Giunchiglia和B. Selman,编辑。加利福尼亚州旧金山,摩根考夫曼出版社。
McGuinness,DL和Wright,J.(1998)。配置的概念建模:一种基于描述逻辑的方法。工程设计,分析和制造的人工智能-有关配置的特殊问题。
马萨诸塞州穆森(1992)。知识共享和重用的维度。计算机与生物医学研究 25:435-467。
Ontolingua(1997)。《 Ontolingua系统参考手册》。http://www-ksl-svc.stanford.edu:5915/doc/frame-editor/index.html
Price,C。和Spackman,K。(2000)。SNOMED临床术语。BJHC&IM-英国医疗计算与信息管理杂志 17(3):27-31。
Protege(2000)。Protege项目。http://protege.stanford.edu
Rosch,E。(1978)。分类原则。认知与分类。RE和BB Lloyd,编辑。新泽西州希尔赛德(Lawrence Erlbaum)出版商: 27-48。
Rothenfluh,TR,Gennari,JH,Eriksson,H.,Puerta,AR,Tu,SW和Musen,MA(1996)。可重用的本体,知识获取工具和性能系统: Sisyphus-2的PROTÉGÉ-II解决方案。国际人类计算机研究杂志 44:303-332。
Rumbaugh,J.,Blaha,M.,Premerlani,W.,Eddy,F。和Lorensen,W。(1991)。面向对象的建模和设计。新泽西州恩格尔伍德悬崖:Prentice Hall。
Uschold,M.和Gruninger,M.(1996)。本体:原理,方法和应用。知识工程评论 11(2)。
[1]我们将类名大写,并以小写字母开头插槽名称。对于示例本体中的所有术语,我们还使用打字机字体。
[2]我们还可以将类视为一元谓词,即具有一个自变量的问题。 例如,“这是葡萄酒吗?” 一元谓词(或类)与二进制谓词(或槽)形成对比,二元谓词具有两个参数。 例如,“这个物品的味道浓吗?” “这个东西的味道是什么?”
[3]有些系统仅使用类指定值类型,而不需要实例类型插槽的特殊声明。
[4]我们选择在本体中仅代表红色端口:白色端口的确存在,但极为罕见。
[5] 在这里,我们假设每个解剖器官是因为我们也想谈一类“约翰1日左肋。” 现有个体的各个器官将在我们的本体中表示为个体。
转:https://protege.stanford.edu/publications/ontology_development/ontology101-noy-mcguinness.html 自动翻译文本